Проблемы с реализацией проектов прогнозной аналитики или что бывает «после того, как заказчик загорелся»

Сергей Щербаков, Технический директор Beltel Datanomics
Поскольку тема с аналитикой Big Data, прогнозной аналитикой, да и в принципе использовании систем ИИ в бизнес-процессах достаточно нова, то проблемы встречаются буквально на каждом шагу.
Начинается все, конечно же, с недоверия и неприятия того, что «железный дурак» может что-то путное посоветовать (классное возражение – «вы получите результат либо абсурдный, либо тривиальный» (с) заказчик), и заканчивая тем, что на данный момент много где бизнес в принципе не использует такую сущность как прогноз. Что сложнее переделать – человека или бизнес-процесс – вопрос сложный и в каждом случае выясняется индивидуально.
Но тему недоверия и неприятия на этапе «до того, как», думаю, раскроем в следующий раз. А вот основные проблемы, с которыми мы сталкиваемся на этапе пилотирования и внедрения подобных систем, я и постараюсь осветить.
Начнем издалека – с методологии. Есть такая методика как CRISP-DM: Cross Industry Standard Process for Data 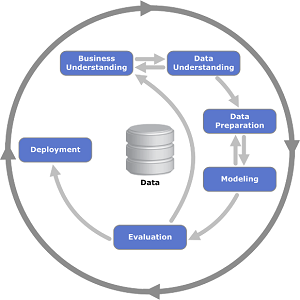 Mining (1999), межотраслевой стандартный процесс для исследования данных. Это проверенная в промышленности и наиболее распространённая методология по
анализу данных (разработки еще прошлого века!). Основными этапами которой являются:
Mining (1999), межотраслевой стандартный процесс для исследования данных. Это проверенная в промышленности и наиболее распространённая методология по
анализу данных (разработки еще прошлого века!). Основными этапами которой являются:
-
Понимание бизнес-задачи;
-
Понимание данных;
-
Подготовка данных;
-
Моделирование;
-
Оценка точности модели;
-
Внедрение в бизнес-процесс.
Допустим, что с бизнес-задачей мы совместно с заказчиком определились (хотя это тоже непросто). Далее мы сталкиваемся с проблемой №1 – Данными. Эта проблема проста и имеет следующие вариации:
-
Данных нет. Точка. Тут остается только пошутить (ибо на самом деле грустно). Многие сравнивают данные с нефтью, но мне все чаще приходит на ум фраза из старого анекдота про пиво в СССР. Пиво было двух сортов: «пиво есть» и «пива нет». Вот и с данными так же.
-
Данные есть (что не может не радовать), но Заказчик их хранит недолго (месяц-два-три), а потом они перезаписываются, стираются, ухудшается точность … нужное подчеркнуть.
И с этой проблемой никакими математическими средствами бороться не получается. Единственное, что можно порекомендовать – собирайте данные. Если вы не анализируйте их сейчас, то это не значит, что этого нельзя будет сделать в дальнейшем. А сколько денег вы сейчас автоматически стираете никто не знает и, главное, не узнает, пока вы не начнете эти данные собирать и анализировать.
Допустим, что данные у нас все-таки первого сорта (т.е. данные «есть») и они за статистически значимый период. И даже опустим то, что иногда на их получение уходят месяцы (месяцы!!! На то чтобы выгрузить пусть большую, но просто табличку!). Но даже после того, как мы получили эти данные, мы практически всегда сталкиваемся с проблемой № 2 – их достоверности и полноты в разных вариантах. Чаще всего данные недостоверны по причинам пресловутого человеческого фактора – небрежности, невнимательности, мошенничества или чего-либо иного. С полнотой данных все и так понятно. Тут как с деньгами: данных никогда не бывает много и всегда хочется знать что-нибудь еще – будь то маркетинговые акции конкурентов в прошлом или курс доллара в будущем. Так что чем больше данных будет, тем точнее будет прогноз.
Небольшое лирическое отступление про неполные данные. Чем больше я работаю в этой области, тем больше понимаю, что если у тебя есть та самая пресловутая «Big Data», то ты король (старый лозунг «кто владеет информацией, тот владеет миром» никто не отменял). С Big Data можно сделать практически все, что угодно и «вытащить из нее» много полезного, приносящего деньги. Но в нашей суровой реальности у людей бизнеса нет этой самой Big Data – просто не было необходимости ее собирать, обрабатывать, хранить и тратить на это ресурсы. Таким образом часто задача аналитики «Big Data» превращается в задачу аналитики того, что есть подручными средствами. Кстати, а знаете ли вы, что любимые многими журналистами (а, как следствие, и читателями) нейросети требуют просто огромного количества данных для обучения и при работе на ограниченной выборке данных показывают, мягко говоря, средние результаты?
В общем, это тема отдельного обсуждения, но, подводя некоторый итог, хочу отметить, что проблема Small Data известна и имеет ряд математических решений, как и методология восстановления данных. Все это сказывается на точности модели, но они есть.
Про построение моделей и оценку их точности много писать не буду – это не проблемы, это работа и даже некоторый фан, поскольку большая часть моделей и подходов придуманы достаточно давно, понятны их плюсы и минусы, ограничения по применимости для тех или иных задач и т.п. И основные рабочие вопросы возникают опять же с данными.
Кстати, я еще не говорил, что весь ИИ (и машинное обучение не исключение) построен на 80-90% на работе с данными? Так вот и на этапе построения модели все и всегда крутится вокруг данных – их преобразования, нормализации, очистки, дополнения … а также поисках дополнительных неучтенных факторов, добавление их в общий датасет с очисткой, преобразованием, нормализацией и так в цикле, пока результат работы модели не станет удовлетворительным. И откуда же здесь фан? А все очень просто – иногда в процессе работы с данными всплывают очень веселые артефакты, иногда проявляются зависимости, которые совсем не очевидны, опровергаются теории, в которые заказчики верили годами … и вот докапывание до сути того или иного явления – это и есть тот специфический фан, который мы получаем. К сожалению, из-за подписанных NDA примеры привести не могу.
Ну и финальная проблема – проблема встройки в бизнес-процесс заказчика. Как показывает опыт, эта проблема решается если не сложнее, то зачастую дольше, чем вся описанная выше математика. Правда, большая часть проблем имеет человеческий фактор. Например:
-
Оптимизация математического решения (т.е. математического прогноза) под бизнес-задачу. Дело в том, что прогноз никогда не имеет точность 100% (если это так, проверьте данные, модель опирается на данные из будущего) и отдельная интересная задача – выбора критерия оптимизация этого прогноза. Это делается не в целях повышения точности модели (все что могли, мы уже сделали), а в целях повышения ее эффективности для бизнеса. И это отдельный повод подумать, обсудить и поработать. И вроде все понятно – сели совместно математики, люди из бизнеса, задали критерии оптимизации, выдали недостающую информацию и сделали. Но это не так просто – вы когда-нибудь пробовали посадить в одном кабинете математика-аналитика и управленца/финансиста среднего звена (да пусть даже и высшего)? Звучит как начало анекдота, выглядит зачастую так же, но нам же не посмеяться надо, нам бы задачу решить. Но тут, барин, помощник нужен.
-
Мы получили отличную модель с прекрасными результатами, но Заказчик никогда ничего не прогнозировал, и под эти прекрасные результаты у него просто нет бизнес-процесса (идея была, а процесса нет … бывает). Так что надо сдвинуть налаженную бюрократическую машину, переписать договоры, закупить кучу софта и железа, наладить новые процессы – это все тема отличного проекта … на ближайшую пятилетку. Пятилетку??? Да к тому времени системы ИИ, по прогнозу некоторых футуристов нас уже поработят, а тут только закончится внедрение первой модели прогнозирования чего-нибудь.
-
Да в конце концов просто недоверие к «железному дураку». Он же тоже иногда ошибается, может реже и меньше (особенно если заказчик потратил время «на подумать» по п.1), но ошибается. И начинаются бесконечные сравнения «а вот здесь он ошибся», «а вот тут он не поймал», «а вот тут ложное срабатывание» и т.п.
-
Ну и отдельная песня – интеграция с системами заказчика. Какой только «зоопарк» не увидишь на просторах нашей необъятной. Хотя, что характерно, брендовость решения совсем не значит, что интегрироваться с ней (т.е. получать из нее данные и возвращать прогнозные величины) будет проще или сложнее. Бывают самописные решения, которые программисты заказчика допиливают за пару дней, бывают решения от известнейших брендов, которые допиливаются месяцами … Вы скажете опять «человеческий фактор»? Наверное, вы правы. Я практически не встречал ни одной системы заказчика, с которой нельзя было бы интегрироваться так или иначе. Вопрос сколько времени и сил на это уйдет.
У того, кто прочитал эту статью может сложиться ощущение, что все у всех с данными плохо, люди криворуки, внедряется все криво и интегрируется сложно. На самом деле это не так. Получение данных, их дальнейшую обработку и интеграцию прогнозов в бизнес можно и нужно проводить быстро и легко. Были бы заинтересованные люди и поддержка со стороны руководства.
 Обсудить
Обсудить
Назад
